I ran all the cells in the the Class 3 notebook. Everything went pretty smoothly. It was fun to test out the voice classifier – it basically worked, but with some funny caveats, e.g. you have to speak loudly to sound angry or else it registers as disgust.
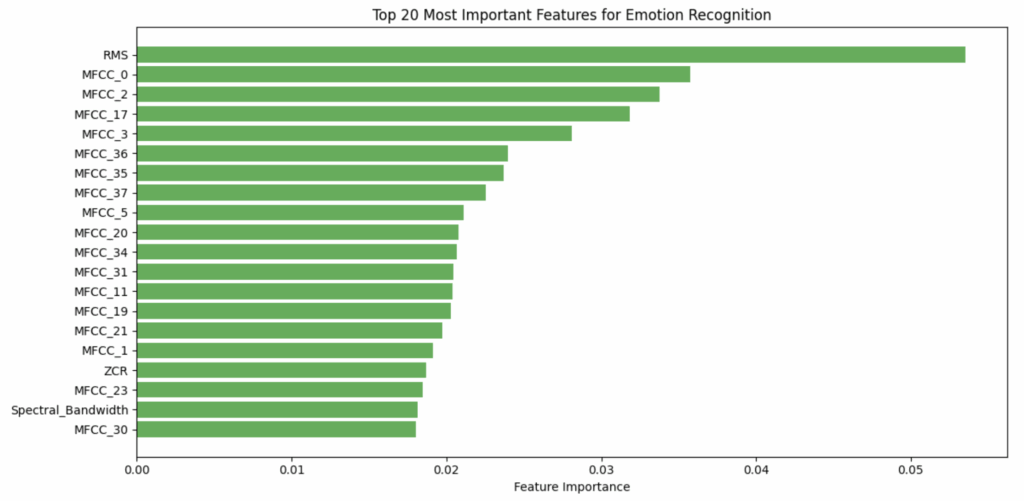
I was surprised that the most important feature was RMS – loudness – instead of the MFCCs. I guess it helps to explain why volume is so important for sounding “angry”.
I tried running the model with just four emotions: angry, happy, neutral, and sad. The accuracy improved from 79% to 86%. Here are the confusions matrices. Before:
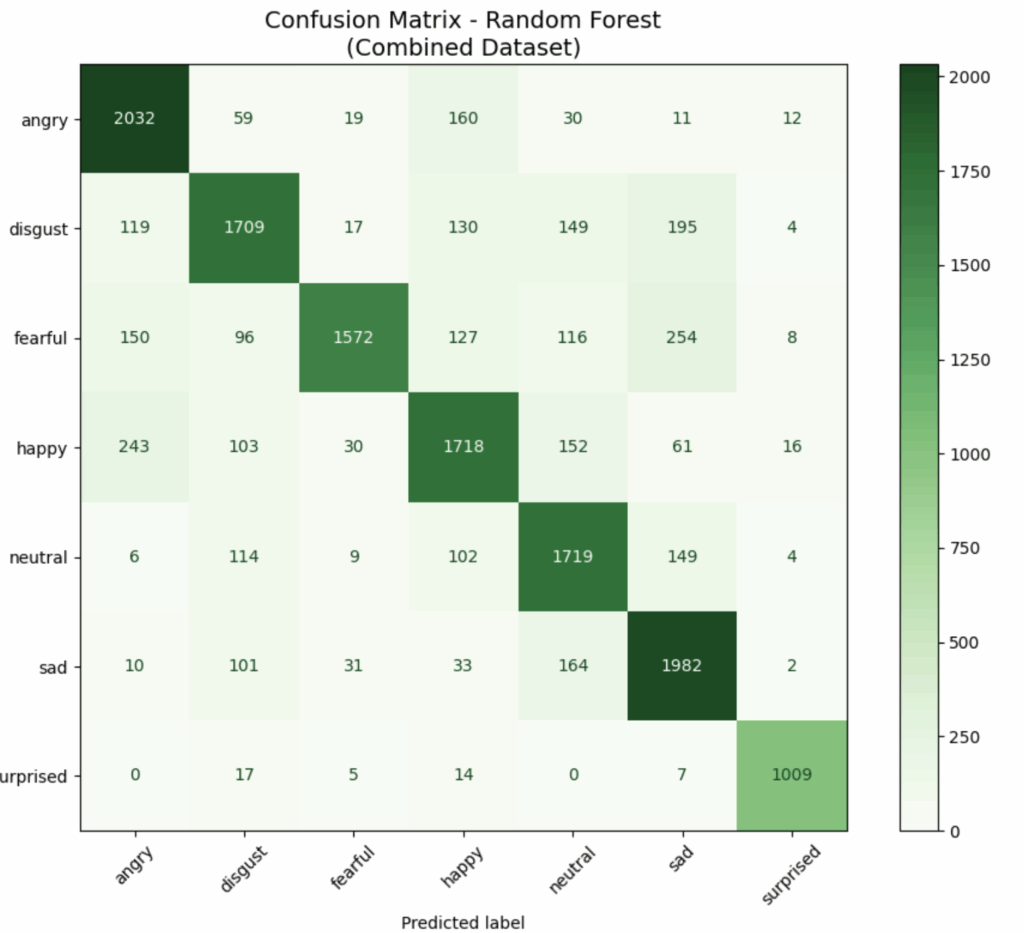
After:
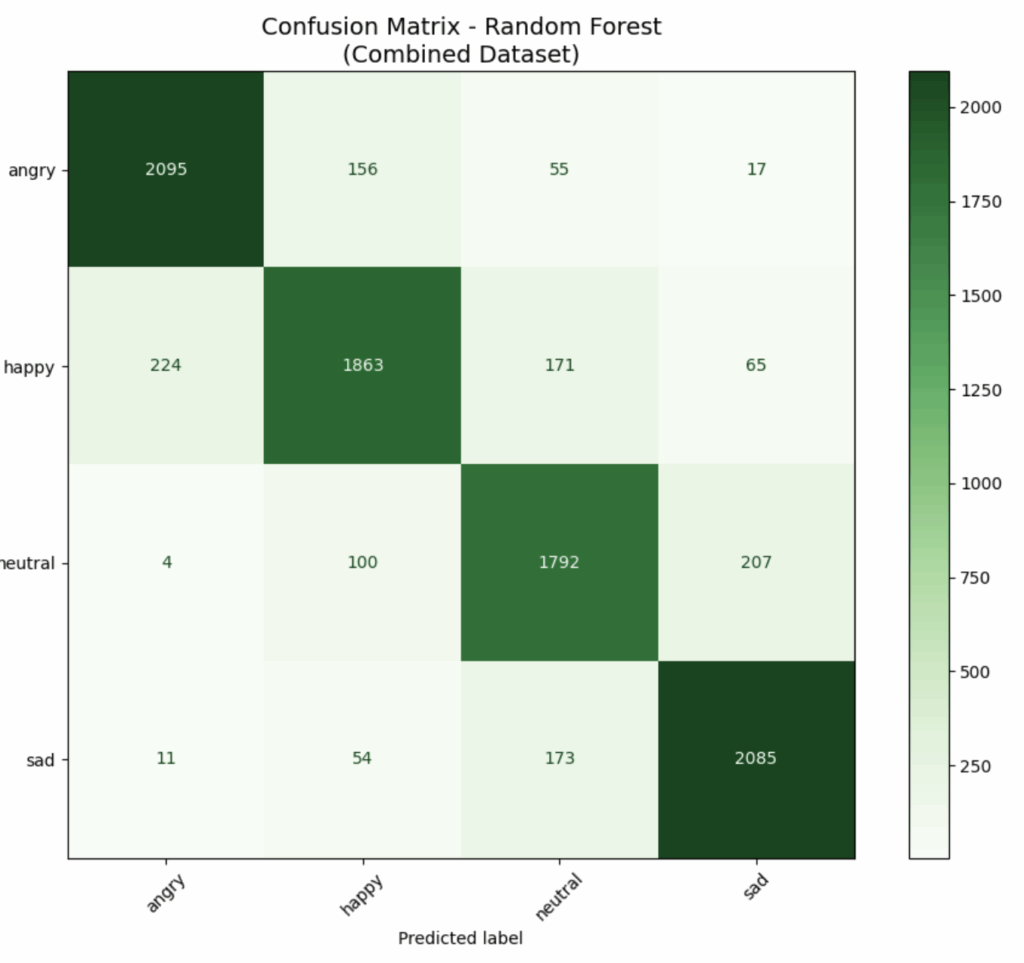
Readings
The Kang article was fascinating. I was a bit puzzled by the way these models seem to all be trained on voice-acted recordings. Listening to the recordings in the datasets we used, I can hear it – they sound super-fake. The distinction between FEA (felt experience acting) and CEA (communication effect acting) was interesting – I would compare it to method acting vs character acting. Either way, it’s still acting – why not use real recordings of people?
While there are potential ethical problems with collecting “real recordings,” it seems easy enough: have subjects speak in a natural, unscripted way to each other. Everyone could have their own mic. They will, unfortunately, know they’re being recorded, but they’ll at least been having authentic, if stilted, interactions. The recordings could be edited and labeled (by humans) into a similar dataset as the ones we played with this week. Why not?
The Pfeiffer article was frightening. I wonder if LADO has been practiced by ICE?